Cистема неперсонализированных рекомендаций видеоконтента в MEGOGO
Для любого видеосервиса система рекомендации контента является одним из ключевых инструментов удержания зрителя. Чем проще зрителю найти новый интересный контент – тем лояльнее он будет к провайдеру и тем больше времени проведет на сервисе. Тот же Netflix настолько много внимания уделил системе рекомендаций, что она даже стала одной из «killer feature» сервиса. Однако у внешне несложного алгоритма есть множество подводных камней.
Как часто в попытках найти интересный фильм для вечернего просмотра вы проводите десятки минут времени, переходя по бесконечным подборкам «30 лучших фильмов этого года» и «100 лучших комедий по версии сайта Х», «10 последних блокбастеров»? Сегодня Megogo может существенно упростить и ускорить поиски, но так было не всегда.
На заре существования сервиса вопрос рекомендаций видео был далеко не самым насущным для решения техническим вопросом. Подборка предположительно интересных для пользователей фильмов была статичной и одинаковой для всех, обновляясь с некоторой периодичностью (поначалу даже постоянной).
Не самое лучшее решение проблемы, хотя тогда нам так не казалось. Подборки были субъективными и из-за этого неэффективными, на их поддержание уходило все больше усилий контент-отдела, а поддержка таких подборок была осуществима не на всех платформах. Например, мы сталкивались с невозможностью эффективного обновления подборок на нашем старом сайте, так что в какой-то момент одна и та же подборка «рекомендаций» висела там около полугода.
Однажды мы решили, что пора сбросить старые костыли.
Список входящих
Основным требованием в нашем ТЗ была необходимость автоматически делать и регулярно обновлять подборку рекомендуемого контента к каждому фильму в нашей базе. При этом, нужно было учитывать всех пользователей в целом, а не только зарегистрированных, так что выбор пал на неперсонализированную систему.
Аналитики предложили основывать систему рекомендаций на метаданных видеообъекта, таких как тип, жанр, страна-производитель, участники съемочной группы и т.д. Это было наиболее оптимальное решение для создания матрицы, но тут же скрывался и первый подводный камень. Чем больше и точнее база данных мета-информации, тем лучше будут результаты рекомендаций. Ту мету, которой мы располагали, нам предстояло существенно улучшить и расширить.
Можно было обратиться к консалтинговым компаниям или онлайн-базам фильмов, таких как TheMovieDB, но в большинстве случаев, их услуги были или существенно переоценены или мета-данные, собираемые компаниями, нам не подходили. Например, на IMDb облако тегов строится с учетом голосов пользователей за каждый тег, однако в большинстве случаев (если только речь идет не про блокбастер) имеют небольшое количество голосов, и потому невозможно определить вес тега в облаке. У TMDB этой проблемы нет, но облако тегов обычно чересчур детализировано. Например фильмы «Интерстеллар» и «Волл-И» оба имеют теги «robot» и «dystopia», т.е. для нашего алгоритма эти фильмы будут похожи, однако в первом фильме мало роботов и много антиутопии, в то время как во втором ситуация обратная.
В итоге мы решили остановиться на примерно десяти мета-параметрах, и самостоятельно доводить нашу базу данных по ним до идеального состояния. Решение, может, не наиболее эффективное, зато сбалансированное по количеству затраченных усилий на реализацию.
Алгоритм рекомендаций
Входящая информация о видео объекте включала в себя id объекта и его мета-данные (например жанр, страну и имена ключевых членов съемочной группы). Дело за малым – обработать полученный массив. Реализация была следующей.
Ежечасно (мы обязаны держать рекомендации максимально актуальными) мы выгружаем информацию из MySQL базы данных, где храним ключевую информацию по контенту. После чего каждый параметр в соответствии со своими весами проходит через алгоритм вычисления косинусного подобия (cosine similarity, он же – коэффициент Отиаи). И в конце концов все обработанные данные сохраняются в MongoDB, чтобы упростить получение запросов и выдачу информации из базы данных.
Что стоит за алгоритмом. В первую очередь, мы создаем n матриц со значениями id – meta parameter и заполняем их бинарными значениями: 1 – если, параметр, к примеру, жанр относится к фильму, и 0 – если нет. Это так называемый принцип «one hot encoding», который используется для корректной оценки сущностей с разными свойствами в одинаковых категориях. Он незаменим в ситуациях, когда простое арифметическое сравнение невозможно, как невозможно, например, оценить «Мстителей» в «Шерлоках Холмсах», или в «Спилбергах».
После формирования базовых матриц соответствия мы считаем косинусное подобие для каждой матрицы и получаем n матриц схожести со значениями id – id, которая и показывает, что некий объект А похож на объект Б, потому что у них одинаковый жанр (или иной мета-параметр).
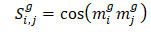
где:

Когда матрицы схожести готовы, мы можем найти линейную комбинацию весов параметров и матриц схожести по параметру.
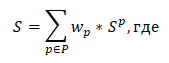

Конечно же большое значение в данной формуле имеет точность весов для каждого параметра. Если бы у нас была такая возможность – мы бы применили байесовскую оптимизацию гиперпараметров для определения оптимальных весов. Но, к сожалению, по техническим причинам мы не можем прибегнуть к этому методу (или его аналогам), поскольку у нас отсутствуют эталонные результаты – ведь пока что это первая реализация системы, выпущенная в продакшн. В общем, пока нам могут с этим помочь разве что A/B-тесты и сравнение различных версий реализации алгоритма.
Проблемы
В первое время после имплементации алгоритма мы столкнулись с тем, что очень часто подборка рекомендуемого состояла только из сиквелов/приквелов фильма (в лучшем случае) или даже из одного и того же фильма, но в разном качестве и с разной озвучкой. Это было связано с тем, что каждый из вариантов единицы видеоконтента у нас заключен в отдельный контейнер, и, соответственно, одинаковые фильмы с разными опциями просмотра имели наибольший коэффициент подобия.
Таким образом, можно было увидеть подборку рекомендуемого полностью состоящую из различных вариантов фильма «Трансформеры» — в русской, английской, украинской озвучке, в разном качестве и т.д. Не слишком информативно для зрителя.
Нам пришлось ввести перед формированием матриц подобия дополнительную фильтрацию и проверку на «слишком высокий коэффициент подобия», а также отсеивать фильмы с настройками, непривычными для пользователя. Например, если зритель смотрит фильмы только в оригинальной озвучке, мы автоматически отсеиваем все локализированные варианты в его выборке.

С другой стороны, эта проблема помогла нам сформировать адаптированные подборки – скажем, состоящие из фильмов только с сурдопереводом – для людей с особыми потребностями.
Что в итоге
Сейчас более 20% пользователей ежедневно пользуются системами рекомендаций Megogo. И как нам кажется – это существенный показатель. Но вместе с тем это не мешает нам продолжать совершенствовать нашу систему. Дальнейшие шаги — внедряем и персонализированные рекомендации для неанонимных пользователей.